
TL;DR – This article is a short run through of how PoshC2‘s shellcode is automatically generated on the fly using binary patching without the need for continued re-compilation. We’ll also go over how we use GitLab CI/CD pipelines to generate the payload files and create the artefact files inside the resources folder, specifically shellcode! DevOps PipeLines is an increasingly useful practise that we are adopting more and more in everyday red teaming tradecraft so if you haven’t had chance to jump on the band wagon it’s time to take a look.

History of PoshC2
PoshC2 has been around since 2016 and has advanced considerably in functionality and capability since its first release, which was hosted on Windows and completely written in Powershell. This blog isn’t intended to be a blast from the past in terms of PoshC2’s history but I thought I would add some context to the backstory of its shellcode generation and how its been used and generated since the first iteration in October 2017.
This article was written purely intended for users (both offensive and defensive) to understand a bit more about the PoshC2 shellcode and how it creates custom payloads without needing to re-compile the code every time. I also wrote this to help me remember when I come to changing it all again after a long time!
Without re-inventing the wheel, we already covered a lot about the history and transformation of PoshC2 in a few conference talks last year. For those who missed out, here is a link to go check it out on YouTube as there is some great content on PoshC2 and EDR evasion (shameless plug I know).
- https://youtu.be/wIhlchiRmKQ (BSides London 2019)
- https://www.slideshare.net/nettitude_labs/powershellisdeadepiclearningslondon

A brief overview from our slides which show the timeline from 2016 until 2020:
2016
- June – v1.0 First Release of PoshC2 (Server/Implant in PowerShell)
- December – v2.0 Released – C# GUI, Daisy Chaining & Portability
2017
- March – v2.1 Removal of C# GUI
- May – PoshC2 Slack channel announced
- July – PoshC2_Python Release
- October – Reflective DLL / Shellcode Released
- November – v3.0 Released with SharpSocks
2018
- February – Readthedocs Documentation Released
- July – v4.0 Released with new Python Implant
2019
- January – v4.8 C# Implant Introduced
- February – Support for 2003/XP using C# Implant
- June – Full SharpSocks Integration for C# and Powershell
- November – v5.0 Released
- November – New Logo and updated documentation (readthedocs)
- November – Complete code base refactor and Python3 transition
2020
- May – v6.0 Released with Postgres support and improved Daisy Chaining
- June – PoshC2 Indicators of Compromise (IoC)
- July – Some big releases coming (check out @Nettitude_Labs for updates soon)
Background
To start with you need to get your head around four key concepts which will help you understand this process even better. These four concepts are:
- Creating a reflective DLL (vs a standard C++ DLL)
- Loading the Common Language Runtime (CLR – managed code) inside unmanaged code
- Creating position independent code (PIC) or otherwise known as shellcode
- Binary patching
In this blog i’ll try and explain these concepts and how they have been instrumental in my understanding of malware creation and how PoshC2 has benefited through these feature enhancements and how they are still widely used today.
Creating a Reflective DLL
If you have never created or messed with C++ DLLs as a red teamer its about time you dive in. I’m by no means a C++ developer but I can work my way around almost any code base, providing its not massively complex and usually the tasks were trying to do aren’t. Even the DLLs that are generated by PoshC2 for its shellcode generation are not overly complex and most of the time others have written great tutorials and examples to help. A few links have been added below and were really useful for me when writing my first Reflective DLL. These can also be injected using many common C2 frameworks, e.g. Cobalt Strike, PoshC2 and may others. A course that also really helped me get better at offensive C++ was at DerbyCon by @scriptjunkie called ‘Memory-Resident Code Analysis and Detection’ in 2018. Although it wasn’t a C++ coding course it was largely about different injection techniques and what things look like in memory. This really helped me understand OpSec concerns and how you may be detected or investigated from a blue team perspective. I know DerbyCon is no more but if you get the chance, I would highly recommend this course.
It is also important when developing DLLs to understand the key differences between a standard C++ DLL and a Reflective DLL. To summarise in my own words, the best way of explaining it is the way of creating a DLL that can be loaded from memory rather than using the traditional method of loading a DLL from disk, using functions like LoadLibrary. This is a vital component to ensure we can migrate into other processes without having to place our code on disk and being worried about host-based Anti-Virus or any cleanup activities that would be required if we wrote files to disk. A reflective DLL therefore takes a specific form. Stephen Fewer was the first person to release this technique and an example project which can be found below for anyone interested in have a play or looking to understand the code-base:
- https://github.com/stephenfewer/ReflectiveDLLInjection
- https://github.com/rokups/ReflectiveLdr
- https://ired.team/offensive-security/code-injection-process-injection/reflective-dll-injection
Although we wont go into this much here (maybe another blog post), these are great resources for defenders to help identify where malicious code may have been injected into a standard process, e.g. detecting the above methods.
- https://gist.github.com/jaredcatkinson/23905d34537ce4b5b1818c3e6405c1d2
- https://github.com/hasherezade/hollows_hunter
Loading the CLR
The C++ DLL we generate needs to initialise the CLR in the current process (if its not there already), create a new AppDomain (always create an AppDomain and don’t use the default as other code could already be loaded here) in the .NET runtime and execute an assembly of our choice from memory. To do this we utilise the same concept from the below links to create unmanaged PowerShell code. This essentially creates the .NET runtime in memory (loading “clr.dll” for v2 and “mscoree.dll” for v4 and above .NET runtimes) including an AppDomain and allows for .NET execution which subsequently either runs our powershell code (which utilises the system.management.automation.dll) or C# implant directly. This enables us to provide process migration in PoshC2 as you can access another process, inject the DLL or shellcode and start the thread which will be our implant.
From a normal process perspective, this may look suspicious if you have a standard process loading an AppDomain that is not making use of any .NET libraries, e.g, svchost or netsh. This is where the operators OPSEC choice’s come in and its really important to do your research before migrating into any process on a target, especially when Endpoint Detection & Response (EDR) tooling exists on the device. Other things which are extremely helpful when migrating are utilising options such as PPID spoofing (which breaks the parent / child process history) and process argument spoofing. Again, all these techniques are just to try and avoid detections and can help stay under the radar in a red teaming engagement when trying to simulate those slightly more sophisticated threat actors.
Some of the lower level threat actors with limited capability will not care about dropping files to disk and therefore techniques such as reflective DLL injection may not always be relevant. Its an important part of adversarial simulation that you understand who you’re trying to simulate and use the correct tools and techniques for the job. If you want to have a play with creating your own DLLs that load managed code, here are a few links that will come in handy.
- https://www.codeproject.com/Articles/607352/Injecting-NET-Assemblies-Into-Unmanaged-Processes
- https://github.com/leechristensen/UnmanagedPowerShell
Creating Shellcode
Currently PoshC2 uses our own C++ DLL with sRDI by @Monoxgas to create custom shellcode rather than writing our own from scratch as that involves assembly in most cases. The binaries with PoshC2 are pre-compiled and added to the project as base64 files, which are then patched on the fly during startup. We’ll talk about binary patching in the next section so that we don’t have to run sRDI or compile a DLL every time you want a new payload or shellcode generated. This is not only a huge time saver for operators but also helps set up the PoshC2 environment, as you don’t need to constantly compile code each time and pull out the shellcode programatically.
Also, another reason we use this method and elected not to write our own was ease of use and a huge time saver as @Monoxgas had already done all the hard work for us and it works really well. There are some great articles out there from the likes of Rapid7 and Matt Graeber which talk about creating shellcode from C++ projects which is on the todo list, but not a high priority at present. A few people have also asked why the shellcode is so big and its because it is doing all of the above inside one DLL rather than using a staged approach like most other C2 frameworks. We could look to create a shellcode stub which utilised WinHTTP or WinInet to download and execute shellcode but then it wouldn’t benefit from a number of security benefits we have in PoshC2 such as the end to end encryption on top of TLS communications. A lot of other C2 frameworks have staged or unstaged payloads which allow smaller shellcode stubs than PoshC2, whereas PoshC2 has the full dropper in all payloads.
Also since writing this, other great projects have come to life such as Donut by @TheWover & @odzhan. We may potentially implement this into PoshC2 in the coming months as it has a Python pip module ready for integration but will require some testing before we choose to integrate and replace the above methods. This project allows you to provide any .NET assembly (in my case, the C# Dropper in PoshC2) as a source file and convert this to shellcode with some additional features embedded such as AMSI bypasses and optional encryption. This process is done in a similar way to sRDI but Donut takes a .NET assembly whereas sRDI must supply a C++ DLL. The Donut shellcode is quite small in comparison to the default PoshC2 dropper and is a good alternative for those advanced users who wish to mix up the shellcode generation before we integrate this fully and create more custom payloads to bypass default signature detections or even more advanced EDR.

Again, I would like to point out that I couldn’t have done all of this without other people’s great work in the community and I have used many online resources to learn what I know now and to help create these projects which PoshC2 now benefits from. Here’s a few links you should definitely check out if you want to learn more about what I’ve discussed or have a go at writing your own:
- https://github.com/monoxgas/sRDI
- http://www.exploit-monday.com/2013/08/writing-optimized-windows-shellcode-in-c.html
- https://blog.rapid7.com/2019/11/21/metasploit-shellcode-grows-up-encrypted-and-authenticated-c-shells/
- https://sevrosecurity.com/2020/04/08/process-injection-part-1-createremotethread/
Binary Patching
To help you visualise the benefits of binary patching I thought I would run you through a very simple C++ proof of concept (POC) that I built in Visual Studio to demonstrate what were doing with our shellcode and DLL generation in PoshC2.

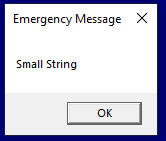
This application is basically a tiny executable that pops a MessageBox which currently prints out a load of A’s and then closes. If we compile the below code and run the application you will get a MessageBox as we would expect which is full of AA’s. Here is the sample code for you to try yourself and follow along.
#include <windows.h>
int main()
{
// char with 30 A's
char char_Patch[] = "AAAAAAAAAAAAAAAAAAAAAAAAAAAAA";
// simple messagebox
MessageBoxA(NULL, char_Patch, "Emergency Message", 0);
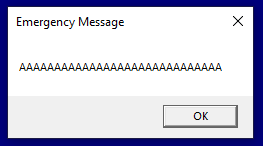
}Once you’ve created and compiled your executable, this is what the output from the application should look like before we have done anything to it.
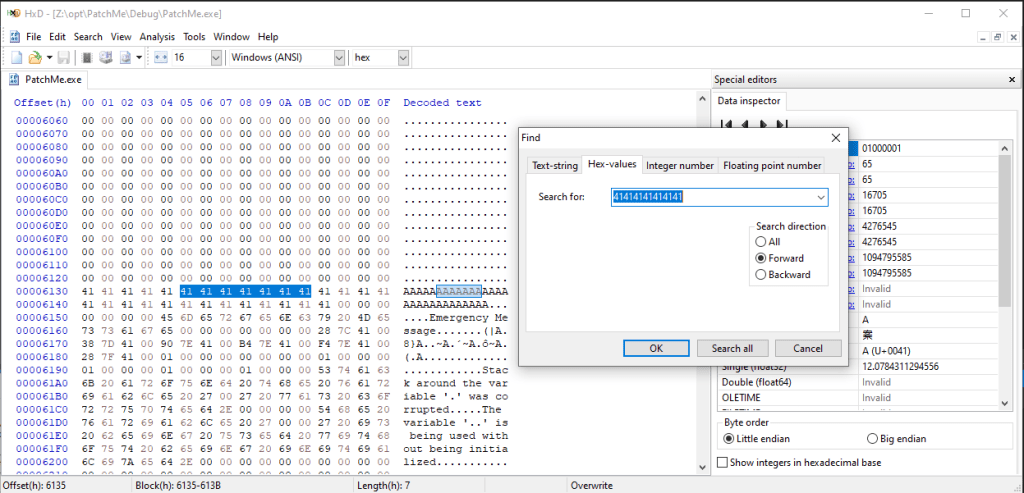
Now lets go a bit deeper and open the compiled application in a hexeditor. My editor of choice is HxD for Windows, as it’s super simple and lightweight to use. If you scroll through the application code you will want to look for a bunch of A’s that will be listed in either ASCII on the right or HEX on the left. You can also search for this using the “Text String” search or “Hex Value” search function. Either way it will take you to the correct offset within the binary file. Now when it comes to binary patching, it’s important to note you can overwrite HEX values without changing the file size, so the structure of the binary is still intact and ultimately leaves it usable. If you modify the length of various structures the binary will most likely not function as it has different code lengths, offsets and the file will not run. This technique shouldn’t be confused with code caves which I may do an article on later this year.
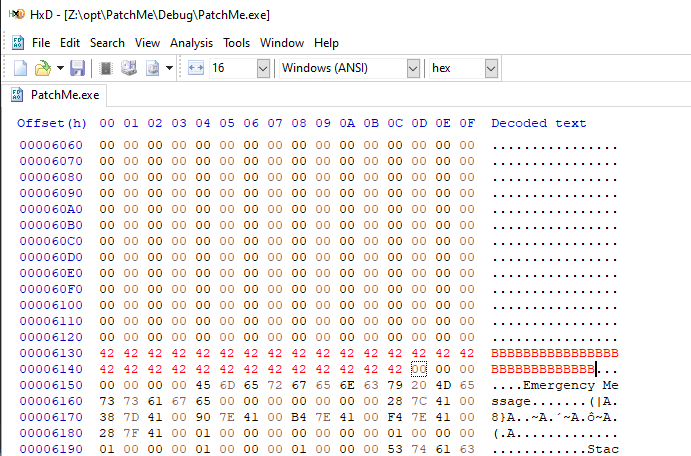
So let’s go ahead and demonstrate how easy it is to patch a binary, for example, let’s overwrite the A’s with B’s or even a mixture of other ASCII characters and save the file. This will backup the original executable and create a new one with your newly stored ASCII characters as shown below. The newly edited characters should show up in red to see what you’ve edited.
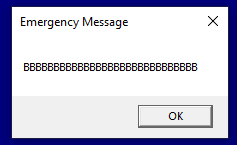
We can overwrite the AA’s quite easy using a hexeditor but it’s not quite as simple when you want to do this programmatically as you need to know file offsets and these can change each time you compile the application. Before we get into automating this, the following screenshot shows us running the application successfully after manually patching the hex code to replace the A’s with B’s.
Obviously this is great and can be really powerful to have this knowledge and functionality but we cannot always guarantee the size of the payload and what happens when you leave some A’s at the end. Can you just delete the content? Well no, its not as simple as that because this will corrupt the binary as it makes the file smaller, similarly to making the sections bigger. So how can we put something in there that is smaller? Well luckily for us we can just add a custom string then append with null characters (0x00) and re-patch the binary as shown below.
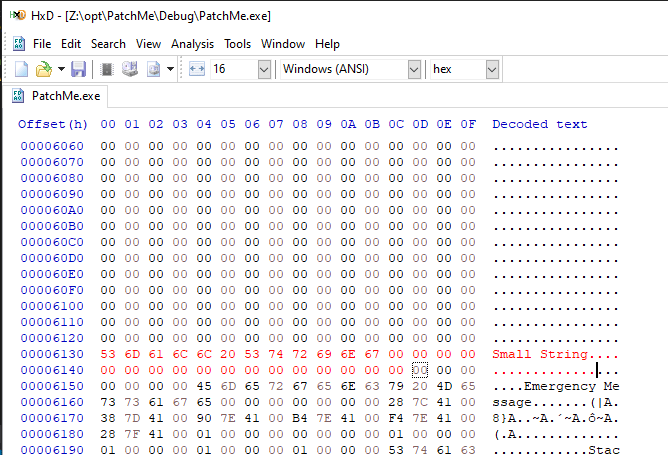
The reason we want to do all of this is so that we can embed a base64’d assembly inside the DLL and then programmatically load this into the CLR at runtime. As we don’t want to compile a new DLL, we add a placeholder of A’s inside the code as a char array and then patch on the fly. If the payload is smaller than the patched variable (which it needs to be otherwise this will also fail), we pad with null characters as shown in the above example.
When we first introduced this concept to PoshC2 we compiled the DLL’s then hard coded the offset so that we could use Python to read the file, move to the offset and write our C# assembly into the file. We would calculate the amount of padding required by using a simple arithmetic function to take the length of the current assembly and the total file size. While this has worked extremely well over time, its not the cleanest code and is quite onerous on us when it comes to modifying the base templates each time we need to modify the code or update something.
If you think every time we want to embed new base templates into the payloads directory we would have to compile 32 and 64 bit DLLs, convert to shellcode using sRDI, base64 and find the offset so we can hardcode this in the payloads file like below:
- $dllOffset_x64 = 0x00012D8
- $dllOffset_x86 = 0x00011D4
As any decent programmer, once you have to do something more than about two times you get that annoyed that you then look to automate this and this is what we did. We had to go away and do some research, but then found a way of dynamically looking through a compiled binary file and finding the A’s and returning the offset. This means we can get away with updating this every time we create new functionality or introduce new bypasses in the DLL without having to update the offsets. I’m sure none of this is ground breaking but it came in really useful and has been a great learning curve so I thought i’d share this for all to have a chance to see. After all, everyone should fully understand what their C2 is doing under the hood as an operator. I have added the patch function below that takes the new assembly and patches the binary using Python3 for anyone who is interested in the code.
def OffsetFinder(patchfile):
with open(patchfile, "rb") as input_file:
file = input_file.read()
file = base64.b64decode(file)
offset = hex(file.index(b'\x41\x41\x41\x41\x41\x41\x41\x41\x41\x41\x41')
return(int(offset, 0))def PatchBytes(patchfile, patchlen):
offset = OffsetFinder(patchfile)
srcfilename = "dropper_cs.exe"
with open(srcfilename, "rb") as b:
dllbase64 = base64.b64encode(b.read()).decode("utf-8")
padding = patchlen - len((dllbase64))
paddingbytes = ""
paddingbytes = paddingbytes.ljust(padding, '\x00')
patch = "%s%s" % (dllbase64, paddingbytes)
output_file = open(patchfile, "r+b")
output_file.seek(offset)
output_file.write(bytes(patch, 'UTF-8'))
output_file.close()GitLab CI/CD Pipelines
Another laborious task was pulling all of this together each time we want to update the DLLs. By this I mean in terms of creating all the different architecture types, e.g. x86 DLL and x64 DLL then converting these to shellcode using sRDI. We also have to create three separate payload types for different reasons. The first is a .NET v2 payload that attempts to launch v2 of the CLR for powershell and downgrade attacks. We then create a payload that only loads v4 of the CLR and finally a payload purely for C#, not powershell, so we actually create six different payloads for both shellcode output and DLL output.
To automate this we used DevOps pipelines with our offline version of Gitlab and use Jenkins and Gitlab runners for automation. I would like to take the opportunity to thank @M0rv4i for the great work he has been doing here as he has educated me in automating most of our development processes and pipelines to streamline our internal development cycles and to introduce some amazing features. Dom Chell @domchell also did some great work in his talk about “Offensive Development” which is on YouTube and is a must see for red teamers.
Once you have your DevOps server setup all you need is a CI yaml file with your configuration, for GitLab these are called .gitlab-ci.yml and if you’re compiling DotNet or C++ this is what one should look like.
- https://gitlab.com/gitlab-org/gitlab/-/blob/master/lib/gitlab/ci/templates/C++.gitlab-ci.yml
- https://gitlab.com/gitlab-org/gitlab/-/blob/master/lib/gitlab/ci/templates/dotNET.gitlab-ci.yml
We have added some “after_script” one liners which essentially take the sRDI powershell script with the compiled DLLs and generates our shellcode artefact files ready for download straight into the PoshC2 repository. This also helps when others are contributing as you can make sure the compiler configuration is the same for all users, e.g. using the correct target type and compiler options as this is not always straight forward:
after_script:
- 'powershell -c {
Import-Module "ConvertTo-Shellcode.ps1";
Get-ChildItem Private -filter *.dll|%{$bytes = ConvertTo-Shellcode -File $_.FullName; [io.file]::WriteAllBytes( "Private/$($_.BaseName)_Shellcode.bin", $bytes) }
}' Another good example of how DevOps pipelines can be used is constant compilation of various binaries and tools using Azure.
Conclusion
Hopefully this blog will be insightful for some red teamers or blue teamers trying to understand shellcode and specifically PoshC2’s shellcode generation. Its been a useful exercise for me to write all this knowledge into one place. In a future blog I would like to go over some cool techniques on how you can debug your shellcode, especially when you want to debug managed code but inside your unmanaged process using Visual Studio and all its great debugging features. We’ll hopefully look to do more posts on DevOps Pipelines as this is something which is being used more and more in all aspects of red teaming.
